5. GPU加速模块
GPU加速模块目前提供对ICGN2D(一阶和二阶形函数)和ICGN3D(一阶形函数)算法的加速。开发者可以通过动态链接库调用。
- 硬件要求:英伟达显卡,显存建议不低于2GB
- 软件要求:Windows 10 以上操作系统,CUDA ToolKit 12.3 或更新版本
GPU加速ICGN模块包括三个文件:头文件(opencorr_gpu.h),静态库(OpenCorrGPU.lib)和动态链接库(OpenCorrGPU.dll)。开发环境的配置与 FFTW 等程序库类似,包括以下四个步骤:
(1)
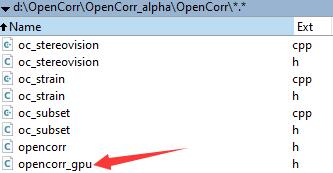
将 opencorr_gpu.h 放到 opencorr.h 所在目录下,如图5.1所示。然后在调用该模块的cpp文件中添加以下语句:
#include “opencorr_gpu.h”;
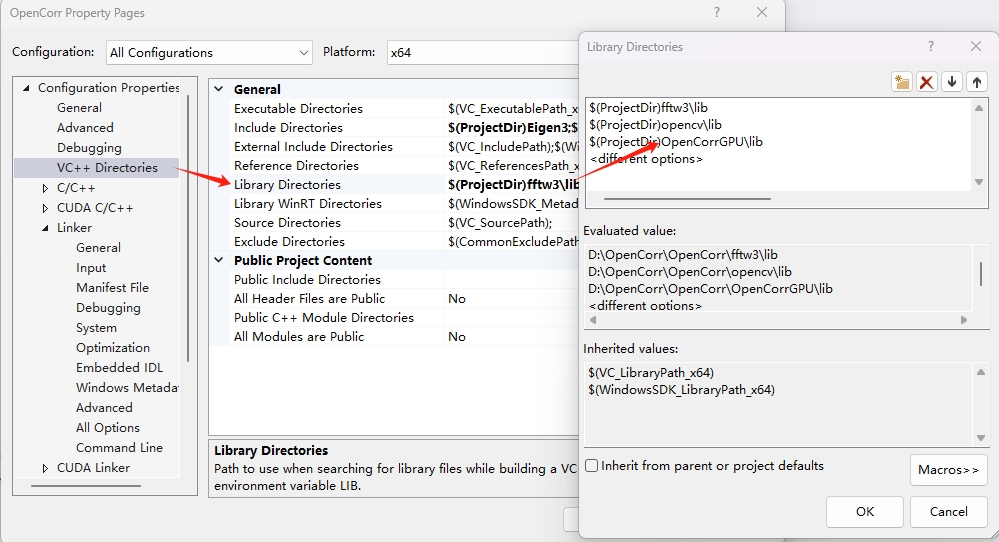
(2)在VS中添加静态库文件的路径(以 OpenCorrGPU.lib 置于图1.1中 opencorrGPU\lib 目录下的情况为例),具体如图5.2所示。点击菜单 项目–>属性–>VC++目录,在“库目录”项里添加开发库静态库文件的目录。
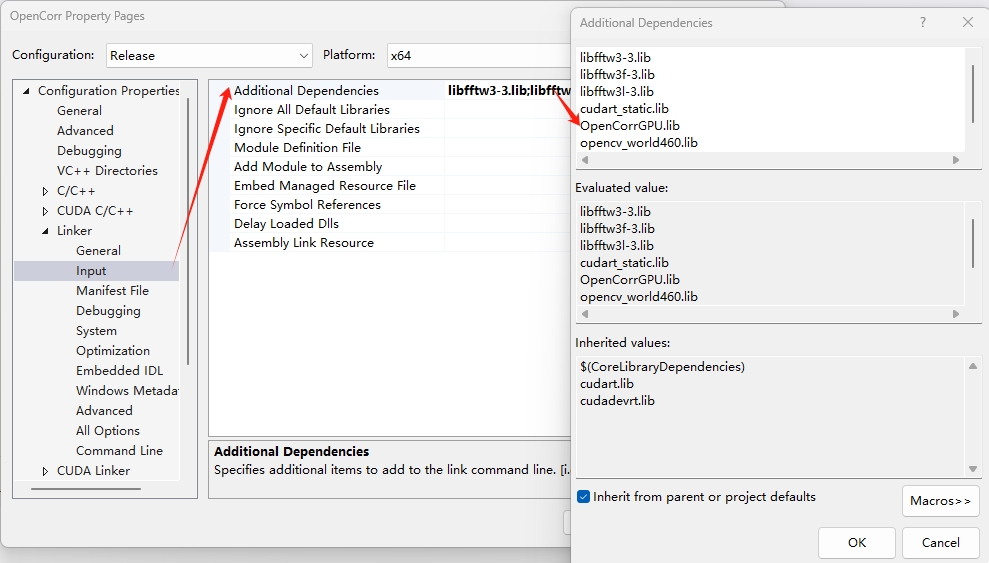
(3)打开项目–>属性–>打开链接器–>输入–>附加依赖项对话框,添加 OpenCorrGPULib.lib 项,如图5.3所示。
(4) 将 OpenCorrGPU.dll 放到编译生成的可执行文件(.exe)同一目录下。值得一提的是,GPU加速模块的性能在不同的硬件上会有所差别,因此我们提供了两个DLL文件,一个将每个CUDA线程块中的线程数设为128,一个设为256。使用者可根据程序在自己显卡上运行的效果选择合适的版本。
(5)GPU加速ICGN模块目前与CPU版本相容。使用者可通过几乎相同的方式创建ICGNGPU实例,并调用其中的成员函数(例如setImages, setSubset, setIteration, prepare, 和 compute)。2D图像由于是通过OpenCV读入的,需要转换为1D数组输入ICGNGPU模块。3D体图像的格式是我们自定义的,因此可直接输入ICGNGPU。更多的细节信息可参阅opencorr_gpu.h和两个相应的例子。与CPU版ICGN不同的是,ICGNGPU的compute函数只接受一个POI数组作为输入,毕竟用GPU加速模块来处理单个或少数几个POI意义并不大。