5. GPU acceleration
GPU accelerated modules currently include ICGN2D algorithm (with shape functions of the 1st and the 2nd order) and ICGN3D (with the 1st order shape function). Developers can use them through calling dynamic link library.
Requirements:
- Hardware: NVIDIA graphics card with memory greater than 2GB
- Software: Windows 10 or newer, CUDA ToolKit 12.3 or newer
GPU accelerated ICGN module consists of three files: head (opencorr_gpu.h), static library (OpenCorrGPU.lib), and dynamic link library (OpenCorrGPU.dll). The configuration in Visual Studio can be summarized as four steps:
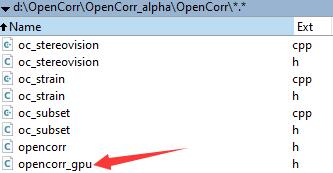
(1) Place opencorr_gpu.h into the folder where opencorr.h is, as shown in Figure 5.1. Then, add the following lines into the cpp file:
#include “opencorr_gpu.h”;
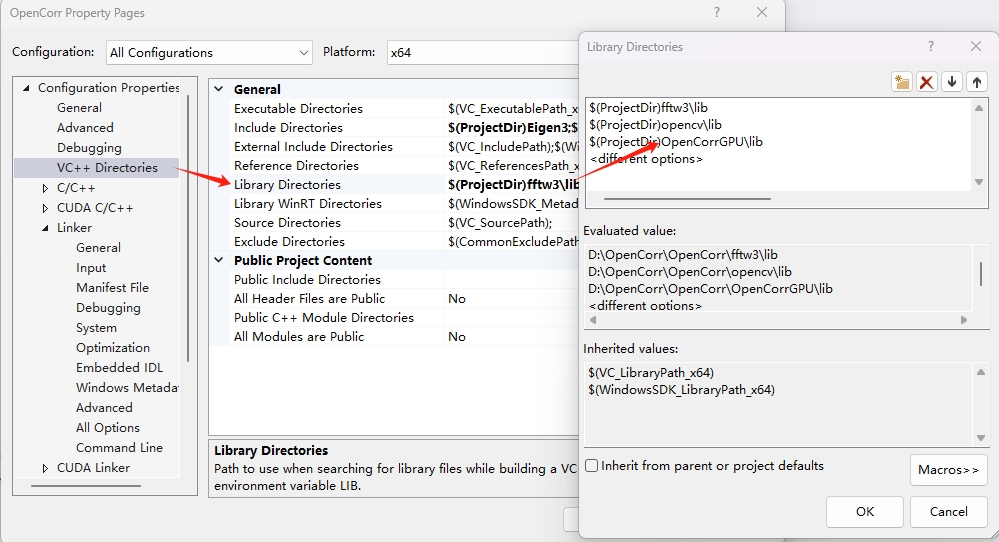
(2) Set the path of static library file in VS (for example, OpenCorrGPU.lib is in folder OpenCorrGPU\lib, see Figure 1.1), as illustrated in Figure 5.2;
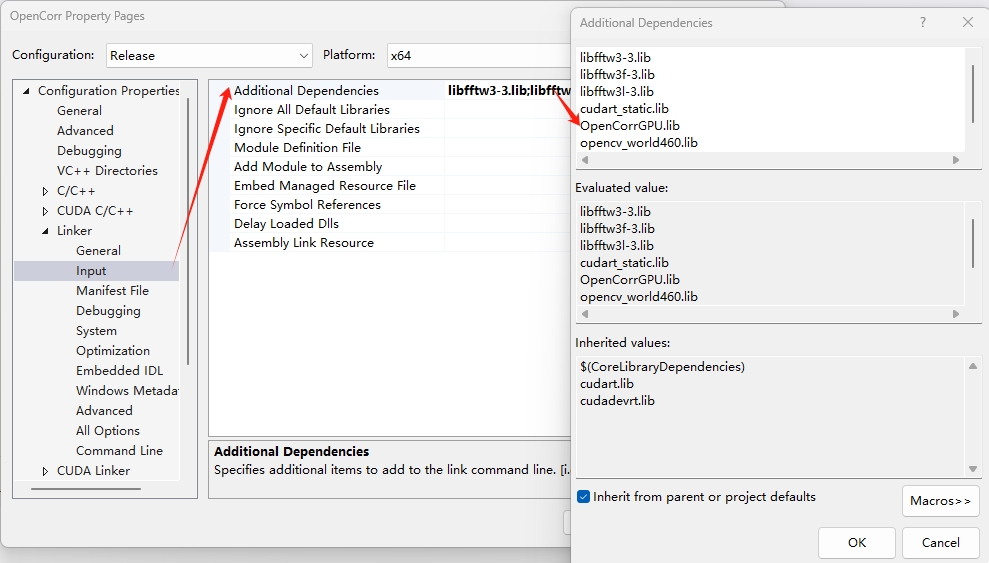
(3) Add OpenCorrGPU.lib as the additional dependencies, as illustrated in Figure 5.3;
(4) Place OpenCorrGPU.dll in the same folder of the built executable program (.exe). It is noteworthy that the performance of GPU accelerated program varies on different hardware. We provide two version of DLL files, one is compiled with 128 CUDA threads per block and the other with 256 CUDA threads per block. Users may choose the one works better on their computer.
(5) GPU accelerated ICGN is consistent with its CPU counterpart. Users can create an instance of ICGNGPU and invoke the functions (like setImages, setSubset, setIteration, prepare, and compute) to make the program in almost same way. 2D images need to be converted to 1D arrays before inputting to ICGNGPU, because they follows the format in OpenCV. 3D images, as the format is defined by ourselves, can be fed into the module directly. More details can be found in opencorr_gpu.h and the two examples. Different from CPU version, function compute() in ICGNGPU only takes a std::vector of POIs as input, since processing a single POI or a couple of POIs does not make much sense for GPU accelerated ICGN.